Data Quality for Unstructured Data
Ensure Unstructured Data Is Accurate, Consistent, and AI-Ready.
Ensure unstructured data is accurate, consistent, trustworthy, and AI-ready, starting with enterprise documents. Explore our Python library for assessing unstructured Data Quality, available in GitHub as a free open source project.
Data Quality for Unstructured Data
Data Quality for unstructured data refers to the ability to monitor, measure, and understand the accuracy, consistency, completeness, and compliance of information that doesn’t fit into structured rows and columns in a data warehouse or database.
Accelerating the next phase of Data Quality democratization, we’ve open sourced our Python library to evaluate Data Quality for unstructured data — enabling documents to become part of your observable data ecosystem.
Why Document Observability Matters
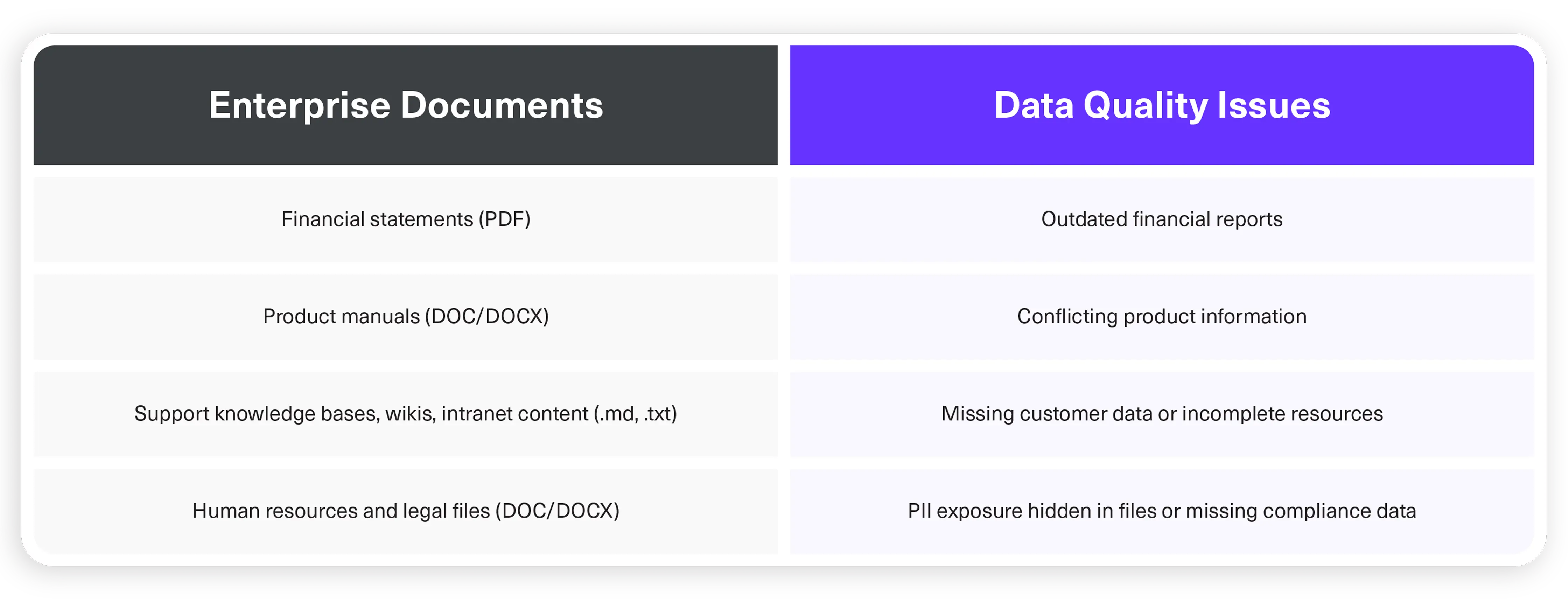
Unstructured data — such as PDFs, Word documents, text files, and internal wikis — contains contextual business information and domain-specific details, critical for AI applications and large language model (LLM) training.
But without document observability, errors and inconsistencies in enterprise documents are usually undetected and unnoticed at scale.
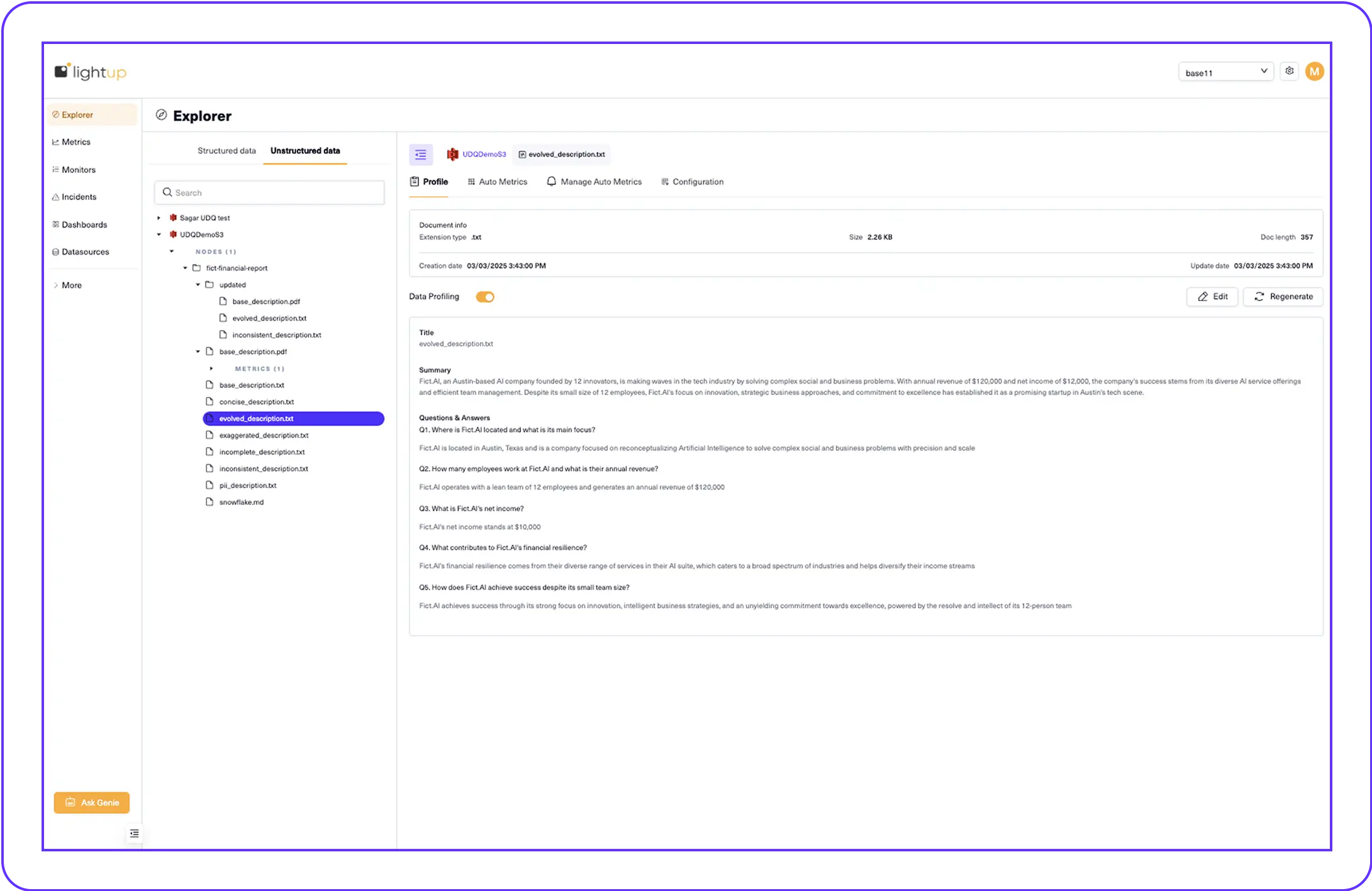
AI Data Profiling for Documents
Lightup automatically generates data profiles for documents using AI, including:
- Document metadata (type, size, creation date)
- Content summary
- 5 auto-generated questions and answers (Q&A) capturing key facts
Profiles can be regenerated or manually edited as needed.
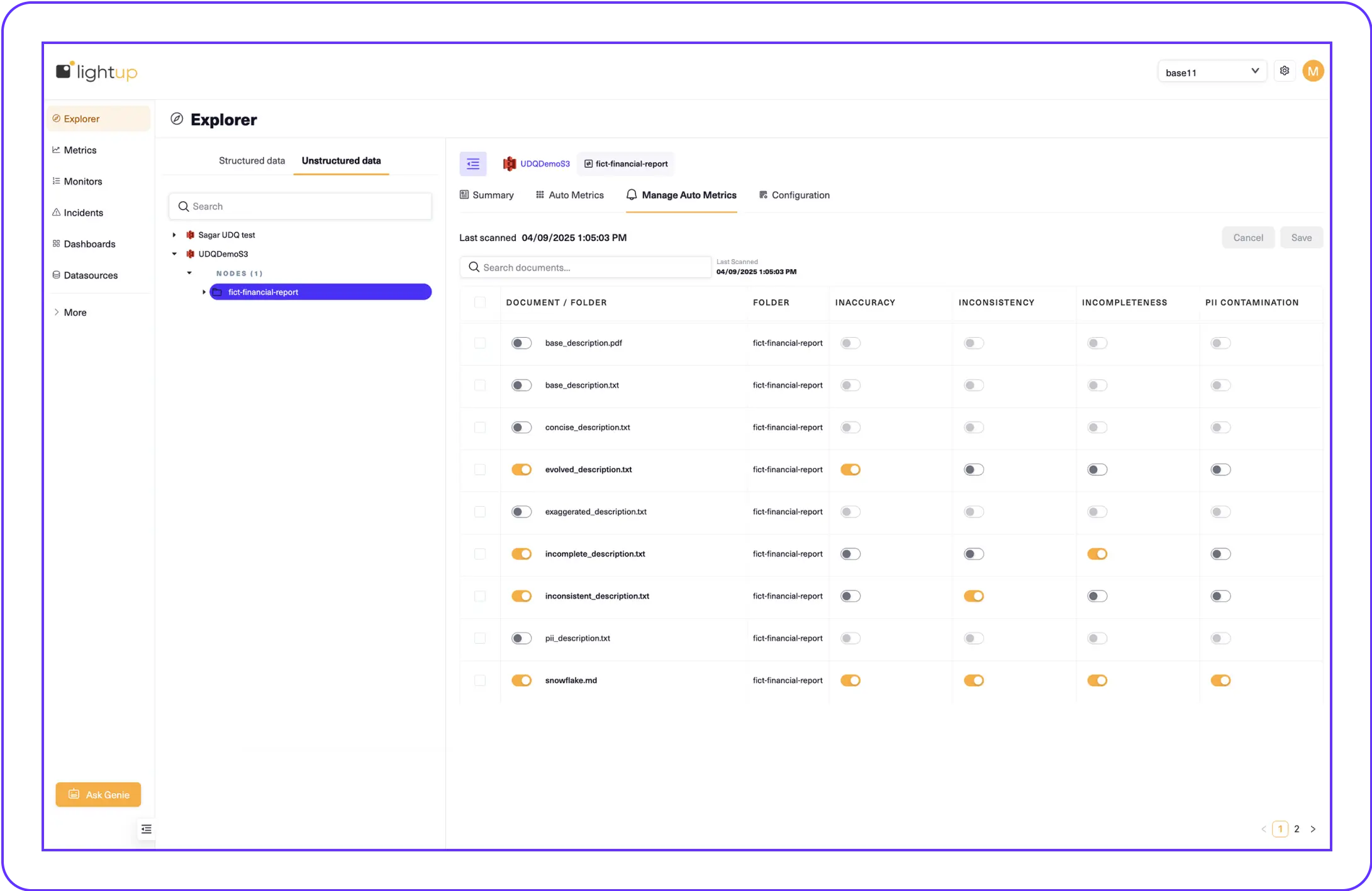
Unstructured Data Quality Metrics

Document-Level Metrics
- Inaccuracy — Detects changes in factual data.
- Inconsistency — Highlights contradictions with side-by-side comparisons.
- Incompleteness — Flags missing information based on original Q&As.
- PII Contamination — Detects names, dates of birth, and sensitive data fields.

Folder-Level Metrics
- Detect inconsistencies across documents.
- Compare multiple documents in a folder for conflicting information.
- Identify version discrepancies.

Custom Metrics
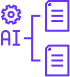
Role-Based Access Control (RBAC)
Lightup provides enterprise-grade role-based access control (RBAC), enabling granular user permissions for all Workspaces: Admin, Editor, Viewer, or Observer.
- Restrict access to PII Contamination metrics by user role.
- Ensure compliance across teams and departments.
Make Documents AI-Ready
Training Domain-Specific LLMs
Retrieval-Augmented Generation
Automated Document Intelligence
Resources
Open Source
- GitHub Repository — Supports documents in Amazon S3 — expanding to Google Drive, Box, and OneDrive. Connect an LLM and S3 bucket, use the Python library to evaluate document accuracy, and run checks for Inconsistency, Incompleteness, Inaccuracy, and PII contamination.
Ensure Unstructured Data Is AI-Ready.